Embedding Model
Embedding model 组件用于生成文本向量表示(embeddings)。
SkillFlaw 内置了一个 Embedding Model 流程组件,已经支持部分常用模型。 如果它不支持你需要的提供商或模型,也可以改用其他 embedding 模型组件。
在流程中使用 Embedding Model
凡是需要生成向量的场景,都可以使用 embedding model 组件。
一个典型用法是构建语义检索流程:
- 添加 Read File 组件,读取一份文本文件,例如 PDF
- 添加 Embedding Model 流程组件,并提供有效的 OpenAI API Key
- 添加 Split Text 组件,把文本切成较小片段
- 添加向量存储组件,例如 Chroma DB,并配置连接信息
- 将组件连接起来:
- Read File → Split Text
- Split Text → 向量存储的 Ingest Data
- Embedding Model → 向量存储的 Embedding
- 若希望用户通过聊天方式检索结果,可再加入 Chat Input and Output 组件
- 进入 Playground 输入查询,测试检索效果
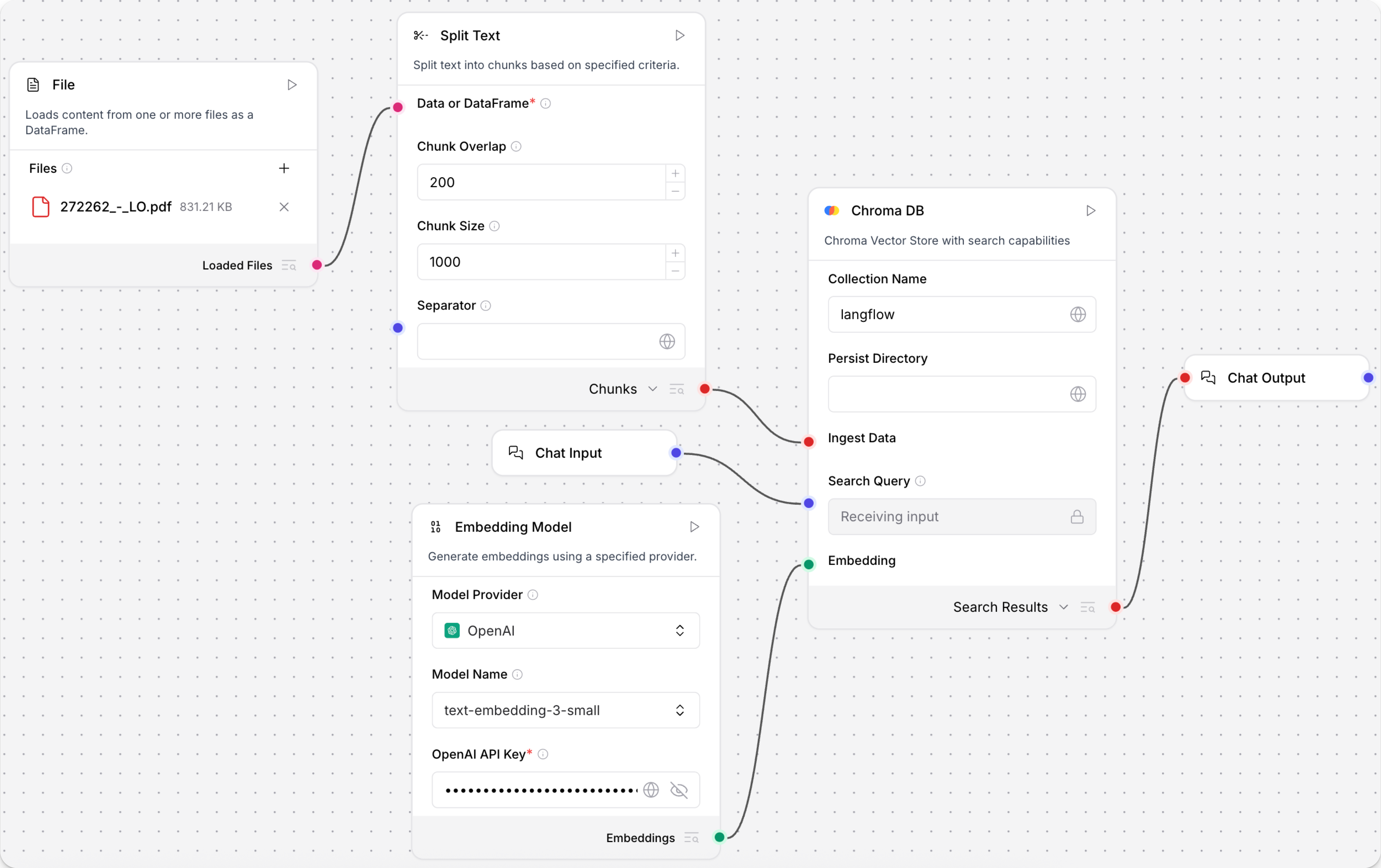
如果 Embedding Model 流程组件不支持你需要的模型,可以在 业务组件 或 Search 中查找其他 embedding 组件,例如 Hugging Face Embeddings Inference。
Embedding Model 参数
以下参数针对 Embedding Model 流程组件;其他 embedding 组件可能有所不同。
有些参数在可视化编辑器中默认处于隐藏状态。 你可以通过组件标题栏菜单中的 控件 来修改全部参数。
| 名称 | 显示名 | 类型 | 说明 |
|---|---|---|---|
| provider | Model Provider | List | 输入参数。embedding 模型提供商。 |
| model | Model Name | List | 输入参数。要使用的 embedding 模型。 |
| api_key | OpenAI API Key | Secret[String] | 输入参数。访问提供商所需的 API Key。 |
| api_base | API Base URL | String | 输入参数。API 基础地址;留空时使用默认值。 |
| dimensions | Dimensions | Integer | 输入参数。输出向量维度。 |
| chunk_size | Chunk Size | Integer | 输入参数。分块处理大小,默认 1000。 |
| request_timeout | Request Timeout | Float | 输入参数。请求超时时间。 |
| max_retries | Max Retries | Integer | 输入参数。最大重试次数,默认 3。 |
| show_progress_bar | Show Progress Bar | Boolean | 输入参数。是否显示处理进度条。 |
| model_kwargs | Model Kwargs | Dictionary | 输入参数。额外传给模型的参数。 |
| embeddings | Embeddings | Embeddings | 输出参数。返回一个 Embeddings 实例。 |
其他 Embedding 模型
如果 Embedding Model 流程组件不支持你的提供商或模型,你可以改用任何能产生 embeddings 的组件。
可以通过 业务组件 或 Search 查找。
将模型与向量存储配合使用
从设计上讲,向量数据是 LLM 应用(例如聊天机器人和智能体)的关键基础。
虽然你可以单独使用 LLM 来处理通用聊天交互和常见任务,但借助上下文感知能力(例如 RAG)和自定义数据集(例如内部业务数据),你可以让应用更进一步。 这通常需要集成向量数据库和向量搜索,以提供额外上下文并定义有意义的查询。
SkillFlaw 提供了能够读写向量数据的向量存储组件,包括嵌入存储、相似度搜索、Graph RAG 遍历,以及像 OpenSearch 这样的专用搜索实例。 由于这些功能彼此关联,因此通常会在同一个流程中,或在一系列相互依赖的流程中同时使用向量存储、语言模型和嵌入模型组件。
要查找可用的向量存储组件,请浏览 业务组件,或使用 搜索 查找你偏好的向量数据库提供商。
示例:向量检索流程
有关在流程中使用向量数据的教程,请参阅创建向量 RAG 聊天机器人。
下面的示例演示了如何在流程中将向量存储组件与嵌入模型、语言模型等相关组件配合使用。 这些步骤会说明重要的配置细节、功能要点以及高效使用这些组件的最佳实践。 这只是一个示例,并不是对所有可能用例或配置方式的唯一规范。
-
使用 Vector Store RAG 模板创建一个流程。
该模板包含两个子流程。 Load Data 子流程会将嵌入和内容加载到向量数据库中,而 Retriever 子流程会运行向量搜索,根据用户查询检索相关上下文。
-
为两组 Astra DB 组件 配置数据库连接,或者将它们替换为你选择的另一组向量存储组件。 确保这些组件连接到同一个向量存储,并且 Retriever 子流程中的组件能够执行相似度搜索。
你在每个向量存储组件中设置的参数,取决于该组件在流程中的角色。 在这个示例中,Load Data 子流程负责向向量存储中 写入 数据,而 Retriever 子流程负责从向量存储中 读取 数据。 因此,与搜索相关的参数只与 Retriever 子流程中的 Vector Search 组件有关。
有关具体参数,请参阅你所选向量存储组件的文档。
-
配置嵌入模型时,可以执行以下任一操作:
-
使用 OpenAI 模型:在两个 OpenAI Embeddings 组件中输入你的 OpenAI API 密钥。 你可以使用默认模型,也可以选择其他 OpenAI 嵌入模型。
-
使用其他提供商:将两个 OpenAI Embeddings 组件替换为你选择的另一组嵌入模型组件,然后相应地配置参数和凭据。
-
使用 Astra DB vectorize:如果你使用的 Astra DB 向量存储已启用 vectorize 集成,则可以移除两个 OpenAI Embeddings 组件。 这样一来,vectorize 集成会自动根据 Ingest Data(位于 Load Data 子流程)和 Search Query(位于 Retriever 子流程)生成嵌入。
提示如果你的向量存储中已经存在嵌入,请确保当前嵌入模型组件使用的模型与之前生成这些嵌入时使用的模型一致。 在同一个向量存储中混用不同的嵌入模型,可能会导致搜索结果不准确。
-
-
推荐:在 Split Text 组件 中,根据嵌入模型优化分块设置。 例如,如果你的嵌入模型 token 限制为 512,那么 Chunk Size 参数就不能超过这个上限。
此外,由于 Retriever 子流程会将聊天输入直接传给向量存储组件执行向量搜索,请确保聊天输入字符串不要超过嵌入模型的限制。 在本示例中,你可以直接输入一个符合限制的查询;但在生产环境中,你可能需要增加额外检查或预处理步骤,以确保满足这些约束。 例如,可以在执行向量搜索��之前,用其他组件先处理聊天输入,或者在应用代码中强制限制聊天输入长度。
-
在 Language Model 组件中输入你的 OpenAI API 密钥,或者选择其他提供商和模型来处理流程中的聊天部分。
-
运行 Load Data 子流程,将数据写入你的向量存储。 在 Read File 组件中选择一个或多个文件,然后在 Load Data 子流程中的向量存储组件上点击 运行组件。
Load Data 子流程会从本地机器加载文件,对其分块,为各个分块生成嵌入,然后将分块及其嵌入写入向量数据库。
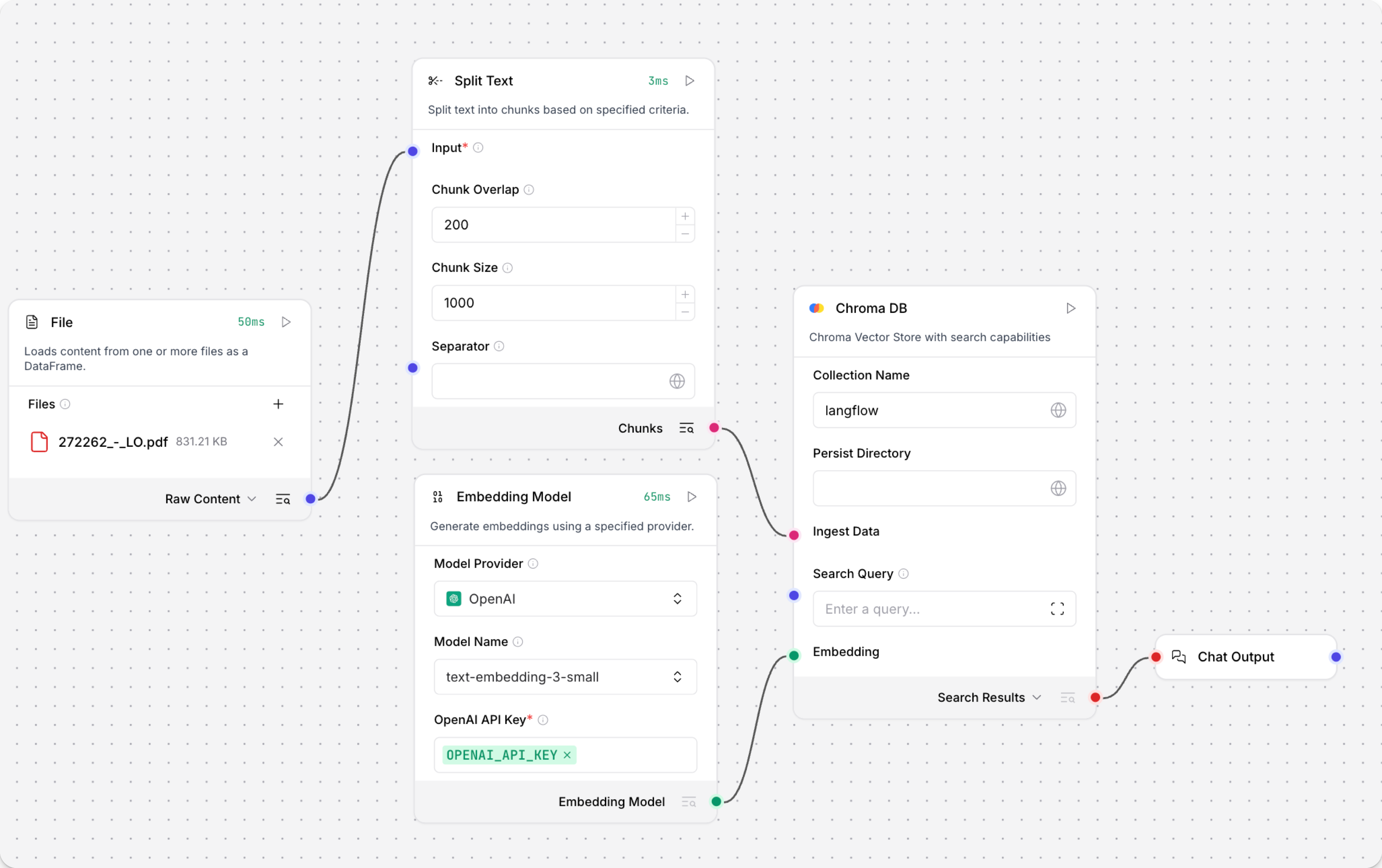
Load Data 子流程之所以与 Retriever 子流程分开,是因为你通常不会在每次聊天时都重新运行它。 你可以按需运行 Load Data 子流程,为向量存储预加载或更新数据。 之后,聊天交互只需使用执行聊天所必需的那些组件。
如果你的向量存储中已经包含可用于向量搜索的数据,那么你就不需要运行 Load Data 子流程。
-
打开 Playground 并开始聊天,以运行 Retriever 子流程。
Retriever 子流程会根据聊天输入生成嵌入,执行向量搜索以从向量存储中检索相似内容,将搜索结果解析为 LLM 的补充上下文,然后由 LLM 根据你的查询生成自然语言回复。 LLM 会结合向量搜索结果、自身内部训练数据以及其他工具(例如基础网页搜索和日期时间信息)来生成响应。
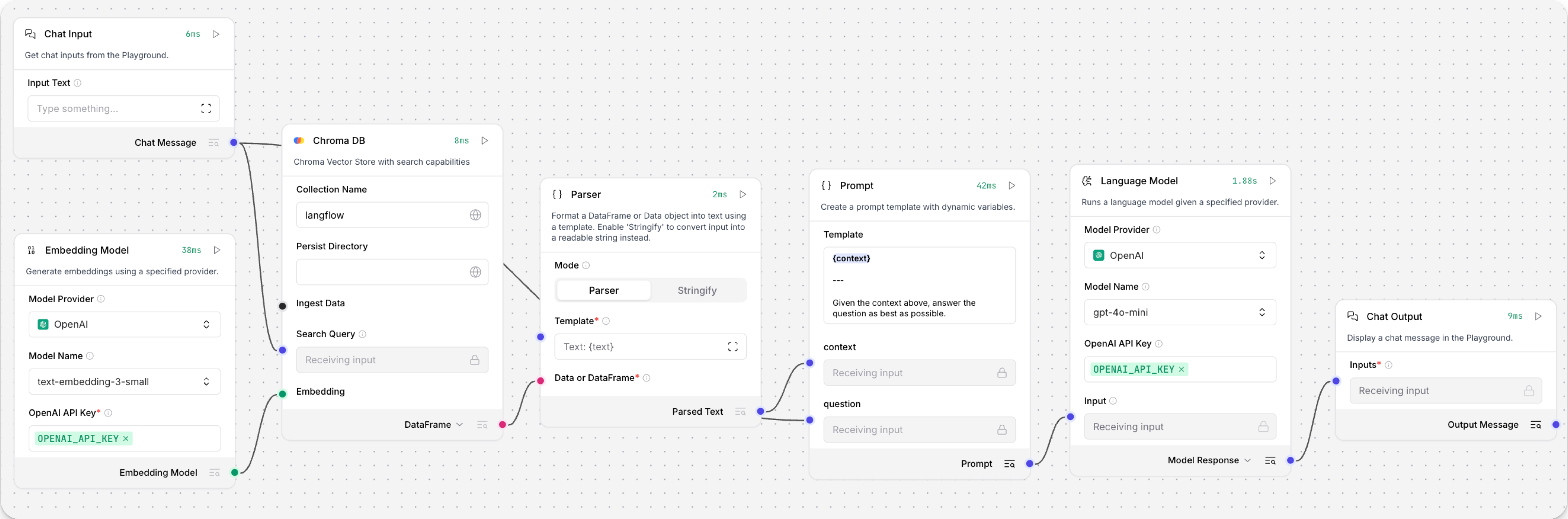
为了避免把整块原始搜索结果直接传给 LLM,Parser 组件会从搜索结果的
Data对象中提取text字符串,并以Message格式传给 Prompt Template 组件。 然后,这些字符串和其他模板内容会被整理成给 LLM 的自然语言指令。你也可以使用其他组件来完成这种转换,例如 Data Operations 组件,具体取决于你希望如何使用搜索结果。
如果你想查看原始搜索结果,请在运行 Retriever 子流程后,点击向量存储组件上的 检查输出。