拆分文本
Split Text 组件会根据分块大小、分隔符等参数把数据拆分成多个 chunk。 它常用于把文本切块后再进行向量化,并写入向量数据库。 相关示例可参阅在流程中使用 Embedding Model以及创建向量 RAG 聊天机器人。
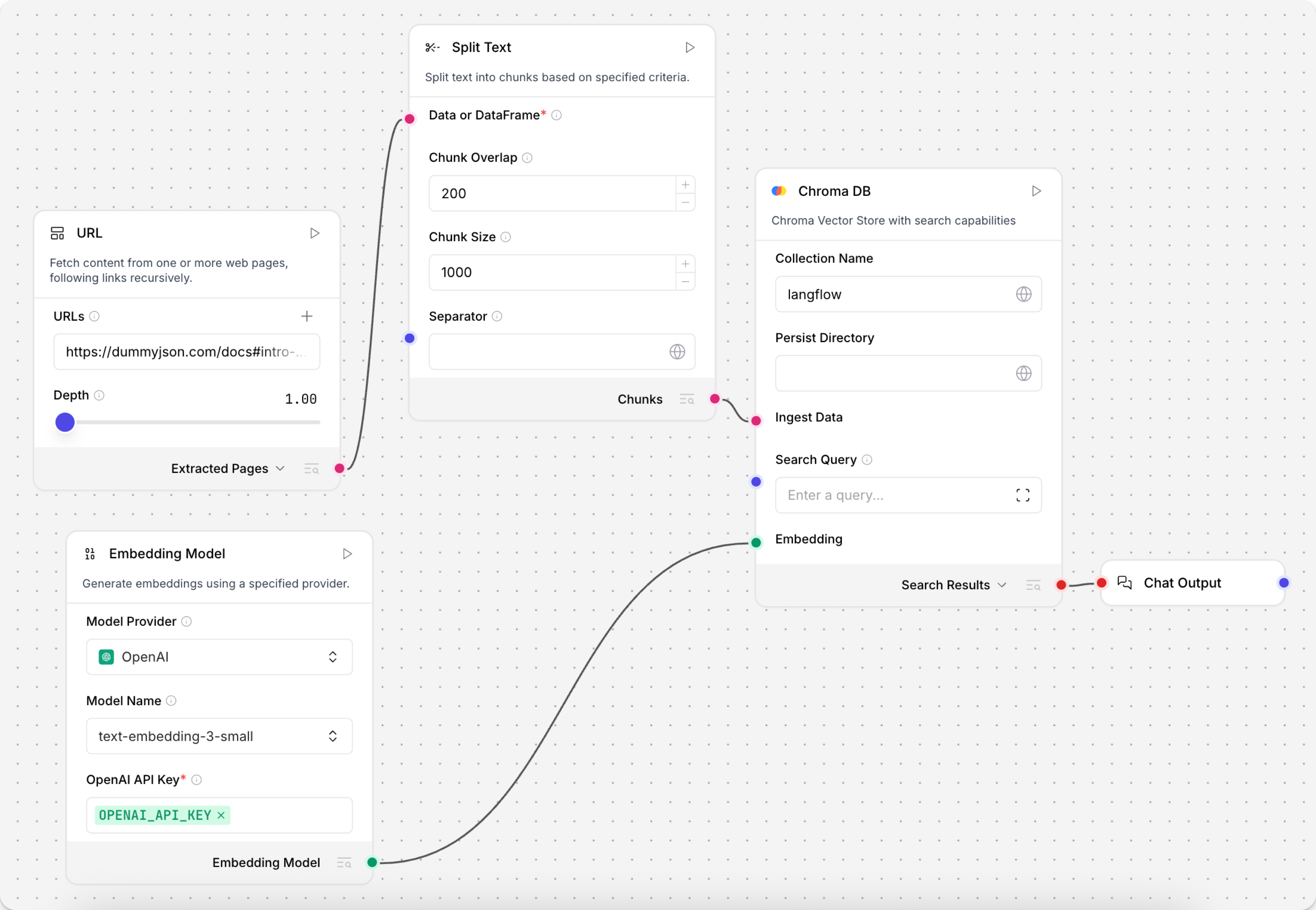
该组件可以接收 Message、Data 或 DataFrame,并输出 Chunks 或 DataFrame。
其中:
Split Text 参数
Split Text 的核心参数决定文本如何被切块,主要包括 chunk_size、chunk_overlap 与 separator。
如果你想测试切块效果,可以先给 Text Input 或 Read File 组件输入一些示例数据,然后在 Split Text 组件上点击 Run component,再点击 Inspect output,查看生成的 chunk 列表及其元数据。
其中 text 列就是根据当前配置生成的实际文本块。
如果切块效果不符合预期,请调整参数,重新运行后再次检查输出。
有些参数在可视化编辑器中默认处于隐藏状态。 你可以通过组件标题栏菜单中的 控件 来修改全部参数。
| Name | Display Name | Info |
|---|---|---|
| data_inputs | Input | 输入参数。要拆分的数据,必须为 Message、Data 或 DataFrame 格式。 |
| chunk_overlap | Chunk Overlap | 输入参数。相邻 chunk 之间要保留的重叠字符数,用于维持上下文连续性。当遇到分隔符时,重叠会以分隔点为边界应用,使后一个 chunk 包含前一个 chunk 最后的 n 个字符。默认:200。 |
| chunk_size | Chunk Size | 输入参数。每个 chunk 的目标长度。数据会先按分隔符拆开,再把小于 chunk_size 的部分合并到该上限以内。但如果初始按分隔符拆分后就已经产生了大于 chunk_size 的块,这些块不会再次被细分,也不会与其他小块合并,而是直接按原样输出。默认:1000。有关重要注意事项,请参阅因 chunk size 导致的分词错误。 |
| separator | Separator | 输入参数。定义拆分字符的字符串,例如 \n 表示按换行拆分、\n\n 表示按段落拆分、}, 表示按 JSON 对象结束位置拆分。你既可以直接填写分隔符字符串,也可以从其他组件以 Message 形式传入。 |
| text_key | Text Key | 输入参数。指定从输入数据中提取文本并进行拆分时使用的文本列键名。默认:text。 |
| keep_separator | Keep Separator | 输入参数。控制输出 chunk 中如何处理分隔符。False 表示移除分隔符;True 表示保留分隔符但不指定位置;Start 表示把分隔符放在 chunk 开头;End 表示把分隔符放在 chunk 结尾。默认:False。 |
因 chunk size 导致的分词错误
当你把 Split Text 与 embedding 模型一起使用时(尤其是 NVIDIA 模型,例如 nvidia/nv-embed-v1),即使模型标称支持更大的 token 上限,你也可能仍然需要把 chunk size 调小到 500 或更低。
Split Text 并不总是严格保证输出 chunk 一定不超过你设置的 chunk_size,因此实际生成的某些 chunk 可能仍然超限。
如果你遇到分词错误,请尝试通过以下方式调整策略:
- 缩小 chunk size
- 调整 overlap 长度
- 使用更常见、切分更稳定的分隔符
调整后,建议重新运行流程并检查组件输出,确认切块结果已经符合你的模型要求。
其他文本拆分器
另请参阅 LangChain 文本拆分组件。