NVIDIA
业务组件 用于按提供商归类那些将第三方服务接入 SkillFlaw 的组件。
本页介绍 NVIDIA 业务组件中的可用组件。
NVIDIA
此组件使用 NVIDIA LLM 生成文本。 关于 NVIDIA LLM 的更多信息,请参阅 NVIDIA AI documentation。
NVIDIA 参数
| Name | Type | Description |
|---|---|---|
| max_tokens | Integer | 输入参数。允许生成的最大 token 数;设置为 0 表示不限制。 |
| model_name | String | 输入参数。要使用的 NVIDIA 模型名称。默认:mistralai/mixtral-8x7b-instruct-v0.1。 |
| base_url | String | 输入参数。NVIDIA API 的基础 URL。默认:https://integrate.api.nvidia.com/v1。 |
| nvidia_api_key | SecretString | 输入参数。用于认证的 NVIDIA API Key。 |
| temperature | Float | 输入参数�。控制输出随机性。默认:0.1。 |
| seed | Integer | 输入参数。该种子用于控制任务结果的可复现性。默认:1。 |
| model | LanguageModel | 输出参数。根据指定参数配置好的 ChatNVIDIA 实例。 |
在 WSL2 上使用 NVIDIA NIM
NVIDIA NIM (NVIDIA Inference Microservices) 提供可自行托管的 GPU 加速推理微服务容器。
你可以使用 NVIDIA 组件,在安装了 Windows Subsystem for Linux 2 (WSL2) 的 RTX Windows 系统上,将 SkillFlaw 连接到 NVIDIA NIM。
下面的示例展示了如何在 RTX Windows system 上通过 WSL2 将 SkillFlaw 中的 NVIDIA language model 组件连接到已部署的 mistral-nemo-12b-instruct NIM。
-
准备你的系统:
-
已根据模型说明部署 NIM 容器
不同模型的前置条件可能不同。 例如,要部署
mistral-nemo-12b-instructNIM,请参阅你在模型部署概览页面中 Windows on RTX AI PCs (Beta) 的说明。 -
Windows 11 build 23H2 或更高版本
-
至少 12 GB 内存
-
基于 Basic Prompting 模板创建一个 flow。
-
将 OpenAI model 组件替换为 NVIDIA 组件。
-
在 NVIDIA 组件的 Base URL 字段中,填写可访问你的 NIM 的 URL。如果你遵循了模型的部署说明,该值应为
http://localhost:8000/v1。 -
在 NVIDIA 组件的 NVIDIA API Key 字段中,填写你的 NVIDIA API Key。
-
在 Model Name 字段中选择你的模型。
-
打开 Playground 并与你的 NIM 模型开始对话。
NVIDIA Embeddings
NVIDIA Embeddings 组件使用 NVIDIA models 生成 embeddings。
有关 embedding 模型组件在 flow 中的使用方式,请参阅 Embedding 模型组件。
NVIDIA Embeddings 参数
| Name | Type | Description |
|---|---|---|
| model | String | 输入参数。用于生成 embeddings 的 NVIDIA 模型,例如 nvidia/nv-embed-v1。 |
| base_url | String | 输入参数。NVIDIA API 的基础 URL。默认:https://integrate.api.nvidia.com/v1。 |
| nvidia_api_key | SecretString | 输入参数。用于与 NVIDIA 服务认证的 API key。 |
| temperature | Float | 输入参数。embedding 生成时使用的模型 temperature。默认:0.1。 |
| embeddings | Embeddings | 输出参数。一个用于生成 embeddings 的 NVIDIAEmbeddings 实例。 |
请注意你的 embedding 模型的 chunk size 限制。 如果文本 chunk 过大,可能会发生 tokenization 错误。 更多信息请参阅由于 chunk size 导致的 tokenization 错误。
NVIDIA Rerank
此组件使用 NVIDIA API 查找并重新排序文档。
NVIDIA Retriever Extraction
NVIDIA Retriever Extraction 组件与 NVIDIA nv-ingest 微服务集成,用于数据写入、处理以及文本文件内容提取。
nv-ingest 服务支持对 PDF、DOCX 和 PPTX 文件类型使用多种提取方式,并包含拆分、分块和 embedding 生成等前处理与后处理服务。提取服务的 High Resolution mode 使用 nemoretriever-parse 提取方法,以便更高质量地处理扫描版 PDF 文档。此功能仅适用于 PDF 文件。
NVIDIA Retriever Extraction 组件会导入 NVIDIA Ingestor client,通过请求 NVIDIA ingest endpoint 写入文件,并将处理后的内容输出为 Data 对象列表。Ingestor 还接受其他文本格式提取所需的额外配置选项。有关如何配置这些选项,请参阅参数。
NVIDIA Retriever Extraction 也称为 NV-Ingest 和 NeMo Retriever Extraction。
在 flow 中使用 NVIDIA Retriever Extraction 组件
NVIDIA Retriever Extraction 组件接受 Message 输入,然后输出 Data。该组件会调用 NVIDIA Ingest 微服务的 endpoint 来写入本地文件并提取文本。
要在你的 flow 中使用 NVIDIA Retriever Extraction 组件,请按照以下步骤操作:
-
准备你的系统:
-
一个 NVIDIA Ingest endpoint。有关如何设置 NVIDIA Ingest endpoint,请参阅 NVIDIA Ingest quickstart。
-
NVIDIA Retriever Extraction 组件要求你在 SkillFlaw 环境中安装额外依赖。要在虚拟环境中安装这些依赖,请运行以下命令。
- 如果你已克隆 SkillFlaw 仓库并从源码安装:
_10source **YOUR_SKILLFLAW_VENV**/bin/activate_10uv sync --extra nv-ingest_10uv run skillflaw run- 如果你通过 Python Package Index 安装 SkillFlaw:
_10source **YOUR_SKILLFLAW_VENV**/bin/activate_10uv pip install --prerelease=allow 'skillflaw[nv-ingest]'_10uv run skillflaw run
-
-
将 NVIDIA Retriever Extraction 组件添加到你的 flow。
-
在 Base URL 字段中输入 NVIDIA Ingest endpoint 的 URL。 你也可以将该 URL 存储为全局变量,以便在多个组件和 flow 中复用。
-
点击 Select Files 选择要写入的文件。
-
选择要从文件中提取的文本类型:text、charts、tables、images 或 infographics。
-
可选:对于 PDF 文件,可启用 High Resolution Mode,以便更高质量地提取扫描文档内容。
-
选择是否将文本拆分为 chunks。
有些参数在可视化编辑器中默认处于隐藏状态。 你可以通过组件标题栏菜单中的 控件 来修改全部参数。
-
点击 Run component 写入文件,然后点击 Logs 或 Inspect output 确认组件已成功写入文件。
-
若要将处理后的数据存储到向量数据库中,请向 flow 添加一个向量存储组件,然后将 NVIDIA Retriever Extraction 组件的
Data输出连接到该向量存储组件的输入。当你运行包含向量存储组件的 flow 时,处理后的数据会存储到向量数据库中。 然后你可以查询数据库以检索已上传的数据。
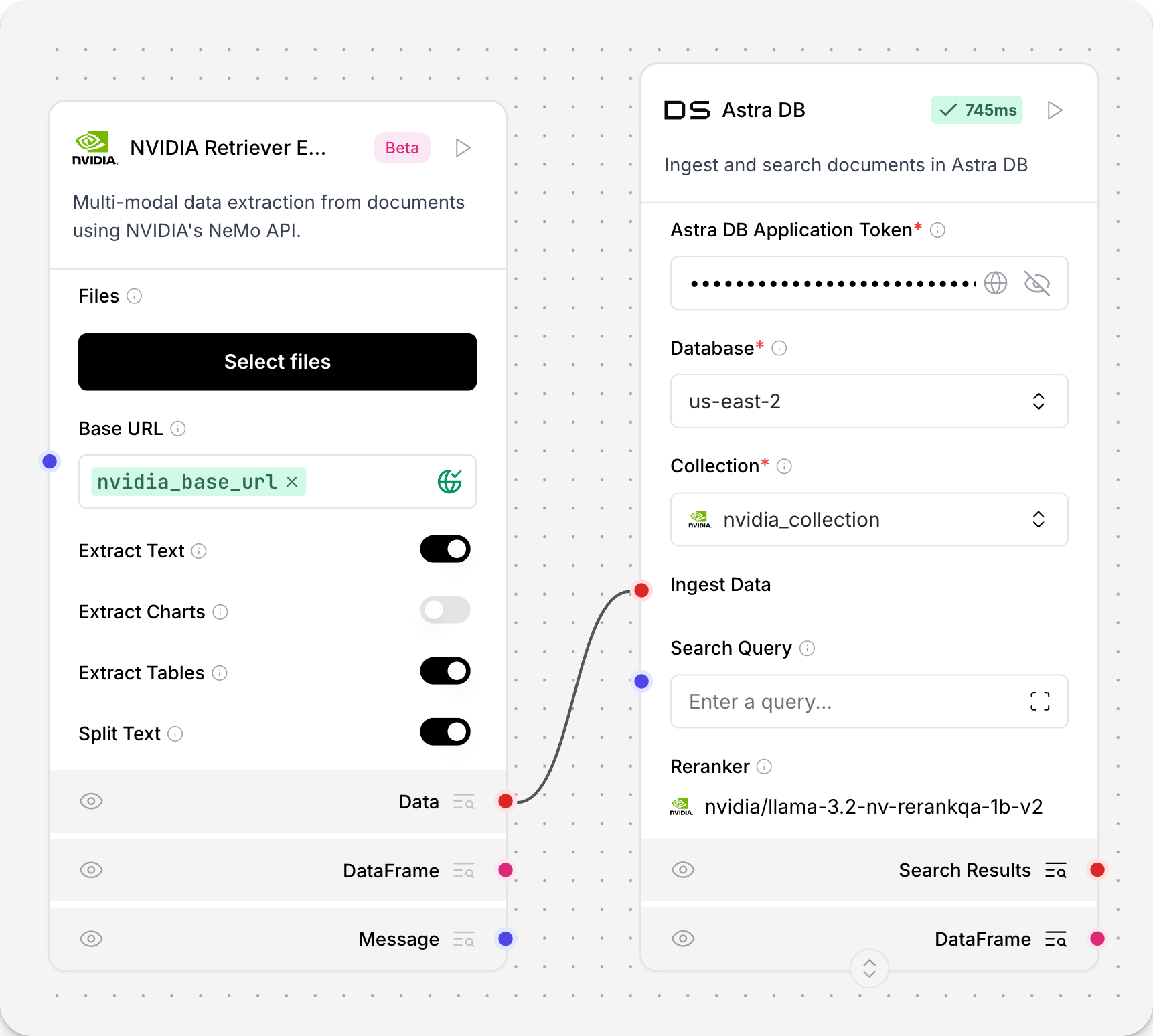
NVIDIA Retriever Extraction 参数
NVIDIA Retriever Extraction 组件具有以下参数。
更多信息请参阅 NV-Ingest documentation。
输入
| Name | Display Name | Info |
|---|---|---|
| base_url | NVIDIA Ingestion URL | NVIDIA Ingestion API 的 URL。 |
| path | Path | 要处理的文件路径。 |
| extract_text | Extract Text | 是否从文档中提取文本。默认:true。 |
| extract_charts | Extract Charts | 是否从图表中提取文本。默认:false。 |
| extract_tables | Extract Tables | 是否从表格中提取文本。默认:true。 |
| extract_images | Extract Images | 是否从文档中提取图像。默认:true。 |
| extract_infographics | Extract Infographics | 是否从信息图中提取内容。默认:false。 |
| text_depth | Text Depth | 文本提取的层级。可选值:'document'、'page'、'block'、'line'、'span'。默认:page。 |
| split_text | Split Text | 是否将文本拆分为更小的 chunks。默认:true。 |
| chunk_size | Chunk Size | 每个 chunk 的 token 数。默认:500。请确认该 chunk size 与你的 embedding 模型兼容。更多信息请参阅由于 chunk size 导致的 tokenization 错误。 |
| chunk_overlap | Chunk Overlap | 与前一个 chunk 重叠的 token 数。默认:150。 |
| filter_images | Filter Images | 是否过滤图像(过滤条件见高级选项)。默认:false。 |
| min_image_size | Minimum Image Size Filter | 图像宽度/长度的最小像素值。默认:128。 |
| min_aspect_ratio | Minimum Aspect Ratio Filter | 允许的最小宽高比(width / height)。默认:0.2。 |
| max_aspect_ratio | Maximum Aspect Ratio Filter | 允许的最大宽高比(width / height)。默认:5.0。 |
| dedup_images | Deduplicate Images | 是否过滤重复图像。默认:true。 |
| caption_images | Caption Images | 是否使用 NVIDIA captioning model 为图像生成描述。默认:true。 |
| high_resolution | High Resolution (PDF only) | 是否以高分辨率模式处理 PDF,以便更高质量地提取扫描 PDF 内容。默认:false。 |
输出
NVIDIA Retriever Extraction 组件会输出一个 Data 对象列表,其中每个对象包含:
text:提取出的内容。- 对于文本文档:提取出的文本内容。
- ��对于表格和图表:提取出的表格/图表内容。
- 对于图像:图像描述文本。
- 对于信息图:提取出的信息图内容。
file_path:源文件名称和路径。document_type:文档类型,可为text、structured或image。description:内容的附加说明。
输出会根据 document_type 而有所不同:
-
document_type: "text"的文档包含:- 从文档中提取出的原始文本内容,例如 PDF 或 DOCX 文件中的段落。
- 直接存储在
text字段中的内容。 - 通过
extract_text参数提取出的内容。
-
document_type: "structured"的文档包含:- 从表格、图表和信息图中提取并经过处理以保留结构信息的文本内容。
- 通过
extract_tables、extract_charts和extract_infographics参数提取出的内容。 - 从
table_content元数据处理后存储在text字段中的内容。
-
document_type: "image"的文档包含:- 从文档中提取出的图像内容。
- 当启用
caption_images时,描述文本会存储在text字段中。 - 通过
extract_images参数提取出的内容。
NVIDIA System-Assist
NVIDIA System-Assist 组件将你的 flow 与 NVIDIA G-Assist 集成,使你可以通过自然语言提示与 NVIDIA GPU 驱动交互。
例如,你可以向 G-Assist 提示 "What is my current GPU temperature?" 或 "Show me the available GPU memory" 来获取信息,也可以让 G-Assist 修改你的 GPU 设置。
更多信息请参阅 NVIDIA G-Assist repository。
-
准备你的系统:
- NVIDIA System-Assist 组件要求在 Windows 操作系统上具备 NVIDIA GPU。
- 它使用
gassist.rise包,所有包含该组件的 SkillFlaw 构建版本都会安装此包。
-
创建一个包含 Chat Input、NVIDIA System-Assist 和 Chat Output 组件的 flow。
这是一个只使用三个组件的简化示例。 根据你的实际场景,flow 可能会使用更多组件或不同的输入输出。
-
将 Chat Input 组件连接到 NVIDIA System-Assist 组件的 Prompt 输入。
Prompt 参数接受自然语言提示,并由 NVIDIA G-Assist AI Assistant 处理。 在此示例中,你将通过聊天输入提供提示词。 你也可以直接在 Prompt 输入中填写提示词,或连接其他输入组件。
-
将 NVIDIA System-Assist 组件的输出连接到 Chat Output 组件。
-
若要测试该 flow,请打开 Playground,然后询问与你的 GPU 相关的问题。 例如,
"What is my current GPU temperature?"。通过 NVIDIA System-Assist 组件,NVIDIA G-Assist 会根据提示查询你的 GPU,并将响应输��出到 Playground。
该组件的输出是一个包含 NVIDIA G-Assist 响应的
Message。 完整操作结果的字符串响应可在Message对象的text键中获取。